Tìm hiểu Command and Query Responsibility Segregation (CQRS)
Đăng lúc: 11:37 AM - 15/12/2022 bởi Charles Chung - 1929CQRS là một mẫu thiết kế thường được sử dụng để phát triển các ứng dụng đòi hỏi về hiệu suất, khả năng mở rộng và bảo mật. Hiểu đơn giản là phân tách vai trò Command (Create-Update-Delete) và Query (Read) với kho dữ liệu.

1. Tổng quan về CQRS
Để hiểu rõ hơn về kiến trúc CQRS, ta sẽ bắt đầu từ kiến trúc truyền thống (n-tier (layer) architecture). Trong kiến trúc N-Tier layer, việc thay đổi dữ liệu thường sử dụng CRUD (create, read, update và delete). Trong kiến trúc này các hành động CRUD triển khai trên cùng một BusinessLogic và sử dụng chung Model như hình dưới:
|
|
| Mô hình N tier/layer truyền thống |

Các bạn có thể hình dung nó giống như 1 kho hàng chỉ có một cửa duy nhất để nhập, xuất hàng cũng như khách hàng vào mua, rõ ràng nếu hệ thống nhỏ, lượng hàng hóa ra vào ít thì không ảnh hưởng lắm, nhưng nếu hệ thống lớn, lưu lượng hàng hóa nhập xuất nhiều chắc chắn sẽ ảnh hưởng tới hiệu suất, khó quản lý...Kho hàng và các hoạt động của nó cũng giống như một ứng dụng web, khi ứng dụng lớn, phức tạp đòi hỏi hiệu xuất cao, dễ mở rộng và bảo mật thì chúng ta cần áp dụng các mô hình hoặc kiến trúc để giải quyết các vấn đề gặp phải. Ở đây mẫu thiết kế CQRS đơn giản là tách khối Business logic thành Commands và Queries:
|
|
| Phân tách Queries và Commands sử dụng chung Domain Model |

Nếu bạn đang cần phân tách rõ Query và Command trên hệ thống với mã nguồn đã dựng sẵn thì bước này chắc hẳn là bước khó khăn nhất.
- Command: thực thi command là cách thức duy nhất để thay đổi state của hệ thống. Command chịu trách nhiệm cho tất cả các thay đổi trong hệ thống. Nếu không có Command nào thực thi, state của hệ thống sẽ giữ nguyên. Thực thi Command không nên trả về bất kỳ giá trị gì.
- Query: là thực thi việc đọc dữ liệu. Nó đọc state của system và có thể filter, aggregate và chuyển đổi form data theo định dạng mong muốn. Query nên trả về kết quả.
Tiếp tục trở lại kiến trúc ở trên, chúng ta có thể chuyển đổi Model trở thành Domain Model. Với Model, bạn hiểu được tập hợp các data container trong khi Domain Model đóng gói thành các nghiệp vụ phức tạp. Với việc chuyển đổi này, chúng ta có thể dễ hiểu Command chịu trách nhiệm cho việc thay đổi state trong những nghiệp vụ phức tạp và nên đặt ở Domain Model. Ngoài ra, chúng ta có thể thấy rõ rằng Domain Model phù hợp cho việc ghi dữ liệu trong khi nó không nhất thiết cần cho việc đọc dữ liệu.
|
|
| Phân tách Queries và Commands Models |
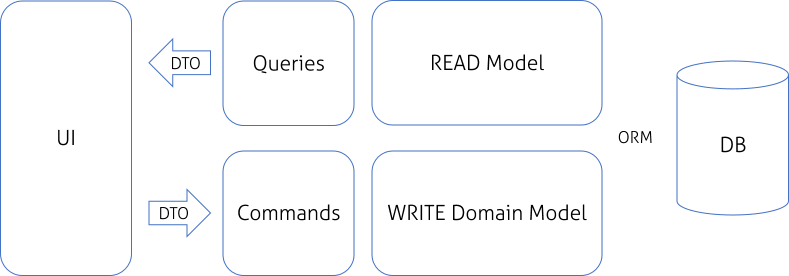
Tiếp theo, chúng ta có thể ánh xạ sử dụng READ Model với ORM (Object Relational Mapping) và sử dụng nó để build các câu truy vấn. Sử dụng ORM sẽ hữu ích để đơn giản mô hình này.
|
|
| Queries có thể nhận dữ liệu trực tiếp từ Database |
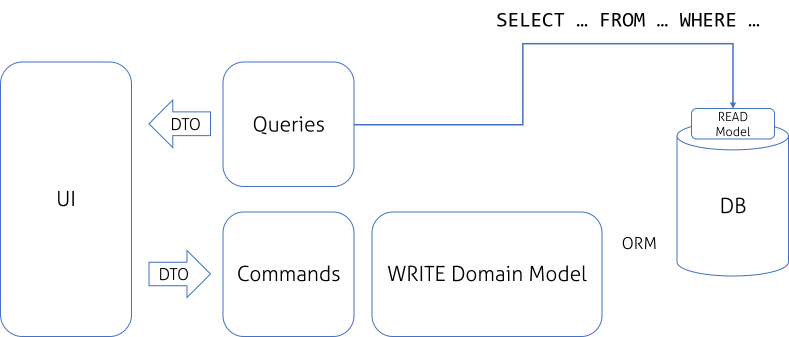
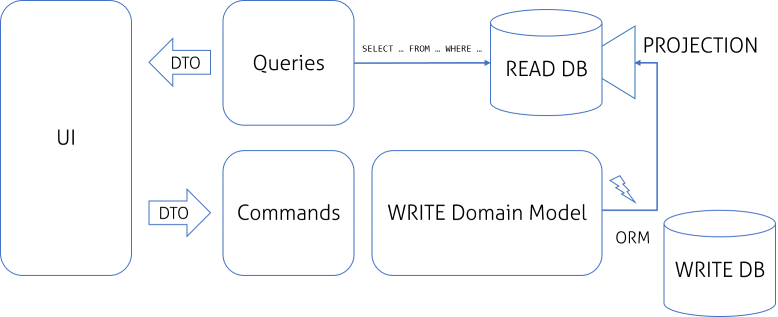
Hiện tại, vấn đề là chúng ta là vẫn có READ và WRITE model tách biệt chỉ ở mức logic level và chúng vẫn dùng chung database. Điều đó có nghĩa là READ model đơn giản chỉ là mức virtualized như DB Views, tốt hơn có thể là Materialized Views. Giải pháp này là OK nếu hệ thống của chúng ta không ảnh hưởng nhiều bởi vấn đề performance. Tiếp theo, chúng ta có thể tách biệt hoàn toàn Data Model. READ Model sẽ được update bởi các event khi WRITE Domain Model thực thi. Đến bước này, chúng ta có thể gọi thiết kế này là CQRS. Thông thường để truy vấn nhanh người ta hay dùng cơ sở dữ liệu READ là NoSQL, còn WRITE là cơ sở dữ liệu quan hệ, việc đồng bộ giữa WRITE DB tới READ DB sẽ sử dụng mô hình Event Sourcing.
|
|
| Việc đọc dữ liệu được cập nhật trực tiếp bởi các sự kiện |
2. Ưu điểm CQRS
- Facilitates distributing dev workload: Việc phân tách các hoạt động CRUD làm 2 phần Queries và Commands sẽ đảm bảo sự độc lập trong quá trình làm việc, thuận tiện cho việc quản lý và giao việc, tránh ảnh hưởng đến nhau.
- Easier maintenance: Dễ dàng bảo trì bảo dưỡng hệ thống, điều này chắc những ai chuyên đi sửa lỗi dạo, fix bug thuê sẽ hiểu được, khi mà đọc logic lưu xuống mà dính với lấy ra tính toán phức tạp thì mất rất nhiều thời gian. Khi mà tôi kiểm tra cơ sở dữ liệu đúng thì tôi biết luống lưu xuống của tôi không bị lỗi thay vào đó luồng tính toán lấy lên của tôi bị sai, việc khoanh vùng lỗi cũng dễ dàng hơn.
- Optimized database design: Đọc ra đọc mà ghi ra ghi, khi cơ sở dữ liệu hệ thống của tôi ưu tiên việc truy xuất dữ liệu sao cho nhanh nhất có thể thì tôi sẽ thiết kế hệ thống tìm kiếm (elastic search), sắp xếp (sorting), đánh chỉ mục (indexing), chia cụm dữ liệu (sharding)… Nếu mà bạn có nghe ở đâu đó một cấu trúc dữ liệu nào giúp bạn tìm kiếm nhanh nhưng mà cập nhập lại chậm thì bạn có thể biết tới Linked List. Vì đơn giản là chúng sắp xếp liên kết với nhau để tối ưu việc tìm kiếm, nhưng mỗi lần thêm vào thì chúng lại phải đi tìm con trỏ để xác định đúng vị trí thì mới thêm vào.
- Easier scalability: Mở rộng và sử dụng tài nguyên một cách linh hoạt hơn.
- Enhanced security: Phân quyền, bảo mật dễ hơn.
Nguồn tham khảo
- https://kariera.future-processing.pl/blog/cqrs-simple-architecture/
- https://blog.ntechdevelopers.com/gioi-thieu-ve-cqrs/
thay lời cảm ơn!
Các bài cũ hơn
- Hiểu biết cơ bản về lập trình hướng đối tượng (OOP) (09:50 AM - 13/12/2022)
- Sử dụng giải thuật MD5 trong các ngôn ngữ lập trình và các hệ quản trị cơ sở dữ liệu khác nhau. (11:23 AM - 08/12/2022)
- Gọi Web API sử dụng Ajax JQuery (09:41 AM - 08/12/2022)
- Tìm hiểu Bridge Design Pattern với ví dụ sử dụng ngôn ngữ C# (08:57 PM - 06/12/2022)
- Cách GET-POST dữ liệu Multipart lên Web API trong ASP.NET Core (10:22 AM - 02/12/2022)












